CIMI Style Guide |
Version 0.08 |
Published Date: Authors: HL7 CIMI Work Group |
Model Granularity, Reuse, and Composition 5
Terminology Binding Guidelines 8
Semantic Model Range Binding 9
Version | Date | Author | Amendment History |
0.1 | 2012-09-13 | Linda Bird | First draft for comment |
0.2 | 2012-10-26 | Rahil Qamar Siddiqui | Revised section 6.6 on Terminology Binding |
Added sub-sections 6.6.1 to 6.6.4 with preliminary details on the main types of terminology bindings within scope for CIMI. More details to be added in due course. | |||
.03 | 2016-11-16 | Susan Matney | Draft for ballot comment |
.04 | 2016-11-23 | Claude Nanjo | Integration of architectural sections |
05 | 2016-11-25 | Susan Matney | Edits |
0.6 | 2016-11-27 | Jay Lyle | Edits |
0.7 | 2016-11-29 | Claude Nanjo | Review of style guide section and edits |
0.8 | 2017-03-14 | Susan Matney | Edits |
0.9 | 2017-03-23 | Claude Nanjo | Edits |
The purpose of the CIMI style guide is to provide guidance to clinical modelers on the use of the CIMI model to represent clinical information. The CIMI style guide documents preferred modeling styles and conventions, approaches to terminology bindings, and describes the usage of the key patterns to address important clinical use cases (e.g., how to model a panel or problem list in CIMI). Please note for the May 2017 ballot cycle, we are primarily focusing on the core reference model, the clinical reference model, and three patterns of clinical models: evaluation, assertions, and procedures, and related archetypes.
In this section, we provide a brief introduction to the following CIMI modelling principles:
The following quality criteria have been proposed for all CIMI models:
CIMI models:
These criteria will be assessed through clinical and technical reviews and through pilot implementations.
The following principles have been proposed to assist in determining the inclusion or exclusion of information within a CIMI clinical model
The following information will be included in CIMI clinical models:
The following information will be excluded from CIMI clinical models:
The granularity of the CIMI model is defined in several layers. The Core Reference Model specifies the primitive and complex types. The Foundational Reference Model defines the foundational constructs from which all clinical patterns are derived. The Clinical Reference Model defines the specializations of the foundational construct relevant in the clinical domain. Archetypes then constrain these structures to define families of objects that differ purely on the constraints they apply to underlying patterns. In a good design, archetype constraints are applied progressively in order to ensure greater consistency at the leaf-level archetypes through the progressive tightening of constraints.
The CIMI model takes a compositional design approach where structures originating from different hierarchies are assembled to form the final product. The Clinical Statement pattern described in the architectural section is an example. The Object Oriented modeling principles of cohesion and coupling apply. Component structures are designed to maximize cohesion and loose coupling. Such an approach enhances consistency, ease of use, ease of maintenance, extensibility, and ease of archetype development through reuse.
Composition should be favored when:
The CIMI Working Group recognizes it is unlikely a one-size-fits-all approach will accommodate the wide variety of clinical and implementation use cases. As such, the CIMI architecture supports alternate representations of the same model to address the requirements of specific use cases. While, generally, such variations in expressivity are not recommended (CIMI defines a ‘preferred’ set of models), it is sometimes inevitable. For instance, interface models may have different modeling requirements than persisted models or logical models.
The CIMI architecture should thus support the definition of iso-semantic models, sets of semantically equivalent models differing primarily in their structure and terminology pre-coordination.
CIMI also intends to support the ability to transform models into their iso-semantic counterparts. In particular, CIMI aims to support:
Once identified, iso-semantic model sets will be defined by the following:
Iso-semantic models can be defined in:
Iso-semantic models varying in their degree of pre-coordination can generally be addressed at the archetype layer through attribute occurrence constraints. For instance, the FindingSiteAssertion reference model pattern specifies two attributes: a bodyLocation and a bodyLocationPrecoord. Two iso-semantic models can be derived - one obtained by constraining out bodyLocation and using a pre-coordinated term for the body location. Another variant of the same model may constrain out bodyLocationPrecoord and post-coordinate the body location in the model.
Iso-semantic reference model classes can be introduced using reference module extensions but this use case will not be described in this document.
Terminology binding refers to “the assertion of a relationship between the information model and the terminology” [CIMI Glossary]. This binding involves attaching terminology concepts, reference sets or expressions to a node or link in an information model.
There are four main use cases motivating terminology binding to CIMI models:
It is proposed these use cases be met by the fulfilment of the following requirements:
All finalised CIMI Clinical Models shall:
All finalised CIMI Clinical Models may (where appropriate):
Information models are often developed independently of clinical ontologies. As a result, many information models align poorly with the terminologies or ontologies upon which they ultimately depend for their formal semantics. Moreover, by not explicitly specifying the model’s semantics, the meaning of the model is left open for interpretation during implementation further hindering interoperability. CIMI is designed to align closely with the SNOMED CT Concept Model with particular influence from the Situation with Explicit Context expression semantics. If the CIMI attribute aligns with the SNOMED CT concept model, attributes will be bound to descendants of Concept model attribute ID 410662002 | Concept model attribute (note, children of Unapproved attribute (attribute) ID 408739003 should not be used). If there is no attribute binding (e.g. temporal attributes such as “start time”) then CIMI will use descendents from the “observable entity” domain if an equivalence exists.
To support terminology bindings to SNOMED CT components not available in the international release, CIMI will develop a SNOMED CT extension in the CIMI Namespace (namespace id: 1000160). This namespace has been allocated and registered by the SNOMED International.
Value bindings will use SNOMED CT wherever possible – however, where the values are outside the scope of SNOMED CT, other terminologies (e.g. LOINC answers) may be selected (on a case-by-case basis).
When a data element is further refined as a specialization (e.g. skin assessment site is a body location), the value set range must come from the range of the parent data element (e.g. skin assessment site is a subtype of body location).
Work is currently being done within the HL7 Vocabulary work-group to define terminology binding semantics that remain valid across multiple implementation domains (V2, V3, C-CDA, FHIR and CIMI). CIMI is an active participant in these efforts and it is our intent to align CIMI Value Set bindings as closely as possible to this effort.
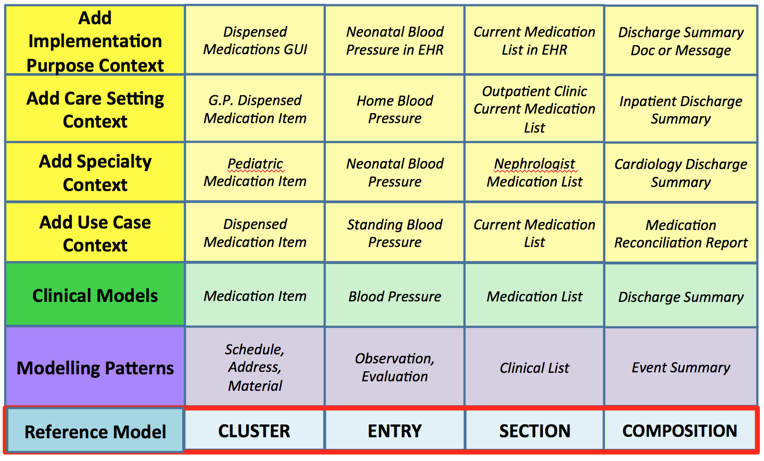
In order to ensure consistency among models, all CIMI clinical models will be based on one or more predefined reference model patterns (top row in table) and corresponding top level archetypes (lowest row in table). These modelling patterns are shown below. The first-layer of Clinical Models, developed based on these modelling patterns, will (wherever possible) be free of specific use-case context, specialty context, care-setting context and implementation-purpose context. Additional levels of context will be added progressively, to enable a maximum level of reuse and consistency between these context-dependent models.
Figure 1: CIMI Modelling Layers
The topic patterns CIMI has developed to date include EvaluationResult, Assertion, and Procedure. They are described below. Future patterns discussed in this guide will include medication administration, encounter, etc. These patterns provide the foundational structure for detailed clinical model archetype instances. The archetype instances can be visualized at models.opencimi.org.
The Assertion Pattern is used to represent a clinical finding. Assertions may:
The assertion pattern is as follows:
Another pattern that could have been selected is an isosemantic EvaluationResult:
The rationale for selecting the first pattern is twofold:
The pattern followed the conclusions of the HL7 TermInfo effort. The HL7 TermInfo project[1] sought to specify guidelines for using SNOMED CT concepts within the HL7 Reference Information Model. The group followed the reasoning of 1) above. Hence, using the first pattern aligns the CIMI pattern with the TermInfo effort.
There are two BaseAssertion subtypes: Assertion and its subtype, FindingSiteAssertion. Note that the reference model introduces two additional subtypes of BaseAssertion: DeviceAssertion and RiskAssertion but these models are not fully defined at this time.
Assertions affirm the existence of clinical conditions, diseases, symptoms, etc. in the patient. A specific Assertion extends BaseAssertion with any additional qualifiers necessary for the specific data element. It also constrains the name code of Assertion to a code representing the condition or disease being asserted. Table 2 shows the example of WoundAssertion. Other examples are CoughAssertion, NauseaAssertion, and DiabetesMellitusTypeOneAssertion, etc.
The following table provides examples of correctly modeled assertions:
Assertion String | Syntax |
The patient has diabetes mellitus type 1 which was diagnosed at age 24 | DiabetesMellitusAssert key: Assertion Code: Diabetes mellitus type 1 (disorder) Context: Confirmed present (qualifier value) ageAtOnset: 24 years |
The patient does not have diabetes mellitus type 1 | DiabetesMellitusAbsentAssert key: FindingAssertion Code: Diabetes mellitus type 1 (disorder) Context: Known absent (qualifier value) |
Table 1: Assertion Examples
A FindingSiteAssertion is an assertion about a finding found on the body. This assertion is a “design by extension” assertion because it contains the additional properties of findingSite and findingSitePrecoordinated which are used to capture the body site affected by the condition.
The FindingSiteAssertion encourages post-coordination. The example below illustrates FindingSiteAssertions. The model intentionally aligns with the SNOMED CT Clinical Findings concept model.
Finding Site Assertion String | Syntax |
The patient has a femur fracture in the right leg | FractureAssert key: Assertion Code: Fracture of bone (disorder) bodylocation: Bone structure of femur body side: Right (qualifier value) Context: Confirmed present (qualifier value) |
The patient has a stage two pressure injury on the right ischial tuberosity | WoundAssert key: Assertion Code: Pressure ulcer stage 2 (disorder) bodylocation: Skin structure of ischial tuberosity body side: Right (qualifier value) Context: Confirmed present (qualifier value) |
Table 2: Finding Site Assertion Examples
An evaluationResult model is a model documenting a characteristic of a patient or a patient-related clinical-value based on a characteristic of the system being observed. An evaluation result may hold the name of a “test” in the key property (e.g., “heart rate evaluation”, “serum glucose lab test”, etc.) and the test result value in the “result” property. Viewed another way, the evaluation result key holds a "question" (e.g., "what is the heart rate?", "what is the serum glucose?") and the “result” holds the answer. Any archetype (a laboratory test, a vital sign, a questionnaire question, etc.) that fits this pattern of a name and a value is modelled with the EvaluationResult pattern.
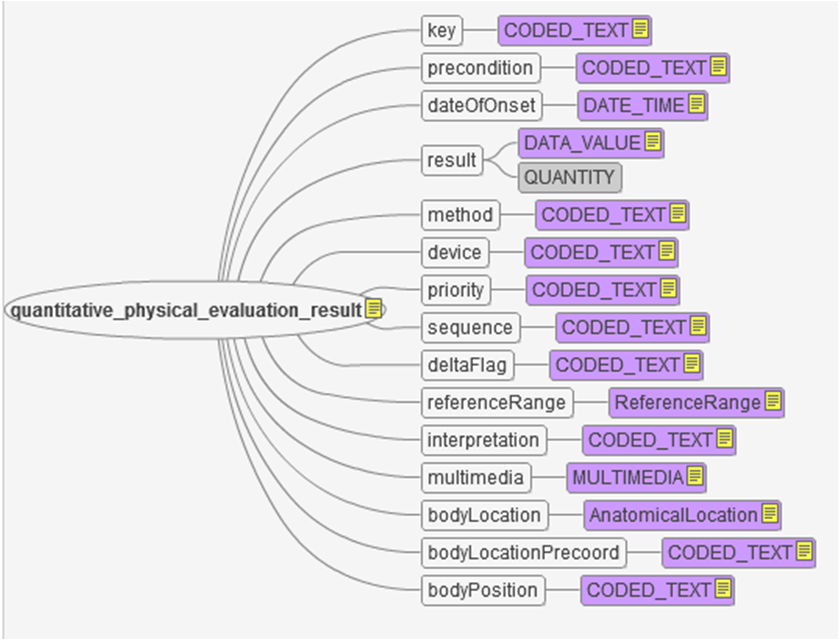
EvaluationResults can be further constrained to define families of detailed clinical models that share common structural characteristics. For instance, the result attribute of the EvaluationResult model can be constrained at the archetype level to QUANTITY, or CODED_TEXT, for instance, thus defining families of DCMs whose results are quantitative and nominal, respectively. The QUANTITY data type consists primarily of a numeric (real) value and a unit of measure. The unit of measure is captured by a code. QUANTITY evaluations are often constrained to a valid “unit of measurement” value set (e.g., “length units of measure”, “mass units of measure”, etc.). The graphic below is a mindmap of the quantitative physical evaluation result.
Figure 2: Quantitative Physical Evaluation Result
The ORDINAL data type consists primarily of a code with an inherent ordering within a set of codes. An example of an ORDINAL component is “severity”. The value set for severity includes codes for “mild”, “moderate”, and “severe”. The codes would have properties or relationships that capture the ordering among them, i.e., “mild” < “moderate” < “severe”.
Coded Text is used when the answer is drawn from a set of coded values. Hair color, urine description, cardiac rhythm, and cervical consistency are examples. In each case, the coded values are adjectives describing the property.
Most archetypes constraining EvaluationResult will specify an observable code for the characteristic to be evaluated (blood glucose, skin moisture, etc.) in the key property and the appropriate range of answers for that characteristic’s result value, whether a set of coded concepts, a quantitative dimension, or some other type. They may also further constrain other properties (body site, specimen), and they may introduce subordinate evaluations (e.g., exercise state).
When using the EvaluationResult pattern it is important to note it does not represent the procedure used to obtain the result. CIMI delineates the act from the description of the state uncovered by the act. The act of evaluating or assessing is captured by the Procedure pattern.
At least three use cases exist pertaining to use of the EvaluationResult pattern (for example, the capture of the result of a heart rate evaluation).
A LaboratoryTestResult archetype contains properties specific to the lab evaluation process. These may include information about the physical process (e.g., specimen) as well as process management information (e.g., status).
A PhysicalEvaluationResult archetype contains properties specific to the clinical evaluation process. These include information about the physical examination process (e.g., patient position, body site).
Physical Evaluation String | Syntax |
The patient’s skin turgor is friable | SkinTurgorEval key: EvaluationResult Code: Skin turgor (observable entity) result: Fragile skin (finding) evaluationProcedure: Inspection (procedure) Context: Confirmed present (qualifier value) |
The patient's systolic blood pressure is 120 mmHg | SystolicBloodPressureEval key: EvaluationResult Code: Systolic arterial pressure (observable entity) result: 120 UnitsofMeasure: Millimeter of mercury (qualifier value) evaluationProcedure: Auscultation (procedure) Context: Confirmed present (qualifier value) |
Table 3: Physical Evaluation Examples
Guideline: Assertion versus Evaluation
In most cases, the decision between using the evaluation result pattern and the assertion pattern is intuitive and straightforward. “Urine color”, for example, is clearly best modeled as an evaluation – the property being evaluated is the color of the patient’s urine and the value (data) of the evaluation is the set of codes representing the colors that may be observed. To model urine color as an assertion would require the creation of a large number of pre-coordinated concepts – the key would be “assertion” and data would be populated by a set of codes such as “amber urine” (meaning “the patient has amber urine”), “clear urine”, etc.
However, this highlights any evaluation model may be transformed into an assertion model. (Conversely, any assertion model may be transformed into an evaluation model.) In the case of urine color, the decision is intuitive. But in other cases, the decision is less clear.
For example, “heart rhythms” (bradycardic, tachycardic, etc.) may be modeled as multiple assertion models (bradycardia, tachycardia, etc.) or as a “heart rhythms” evaluation model whose data is constrained to a value set (containing “bradycardic”, “tachycardic”, etc.).
The general guideline is if it is most natural to think of the data element as a noun – as a condition or state that exists in the patient – model as an assertion or set of assertions. If the statement about the patient is most naturally thought of as a name/value pair (i.e., a noun representing the property and an adjective representing the value), such as “hair color” = (“black”, “brown”, “blonde”), then model it as an evaluation. However, it is important to note both styles are allowed and the true determinant of their use is whether a result for a given criteria other than true/false, present/absent is specified.
This discussion highlights the importance of iso-semantic models. Even if one model or set of models can be agreed upon for the storage model (e.g., assertion models for “bradycardia” and “tachycardia” instead of an evaluation model with “bradycardic” and “tachycardic” as values), inevitably there will be use cases (data entry, messaging, reporting, etc.) for the other model and a need to identify cases where different modeling patterns describe semantically identical phenomena: these patterns are iso-semantic. An essential (as of now unfulfilled) requirement is for a mechanism of identifying iso-semantic models, managing iso-semantic groups, and transforming between them.
It should be noted, the Assertion vs. Evaluation topic is solely concerned with the structure and schema pattern used to capture clinical information. Choosing Assertion vs. Evaluation patterns has nothing to do with whether the information being captured is subjective vs. objective.
Procedure models are used to represent actions taken related to the care of a patient such as peripheral IV placement, delivery of a warm blanket, dressing change, ambulation, patient education, etc.
The CIMI Procedure is a base class for a number of anticipated specializations such as surgical, imaging, and laboratory procedures. The CIMI Procedure Model is aligned with the SNOMED CT Procedure Concept Model when such an alignment exists.
A number of clinical statement archetypes that reference Procedure as the topic of the statement have been introduced to illustrate (1) a proposal for a procedure, (2) the performance of a procedure, and (3) a procedure that has not been performed. Note these clinical statements are composed by the association of the appropriate context with the Procedure topic, namely, the Proposal, Performance, and NonPerformance statement contexts.
As the procedure reference models are still evolving, archetypes for procedures are yet to be modeled and will be described in the Sept. 2017 ballot.
[1] Using SNOMED CT in HL7 Version 3; Implementation Guide, Release 1.5, DSTU Ballot 4 - May 2009 (expired)